
Diving Deep into Containers and Docker
To be a real master of anything, you need to understand what's going on under the hood


Note: Majority of the content has been taken from blogs in the Resources Section. Do visit them and read. I have compiled and added graphics and tried to give it a timeline.
Objective 🎯
- Understand what problems containers solved
- Learn about the building blocks of containers (namespaces, cgroups, layers)
- Look at the brief history of containers and Docker
- Learn about why and how Docker modularized its daemon
- Understand what is Open Container initiative
- Learn what goes under the hood of Container Runtime.
Getting Started
Before we start talking about containers, we need to know why containers came in the first place and what problem they solved!
The Old times..⌛
In past, we were only able to run one application per server as we didn't have the technology to run multiple applications on the same server.
IT teams had to buy overpowered servers as they didn't know the performance requirements of the applications. As a result, most servers used to work at 5-10% of their potential capacity. This wasted money and resources.
Here come the Virtual Machines...💥
Virtual Machines came in and solved the problem!
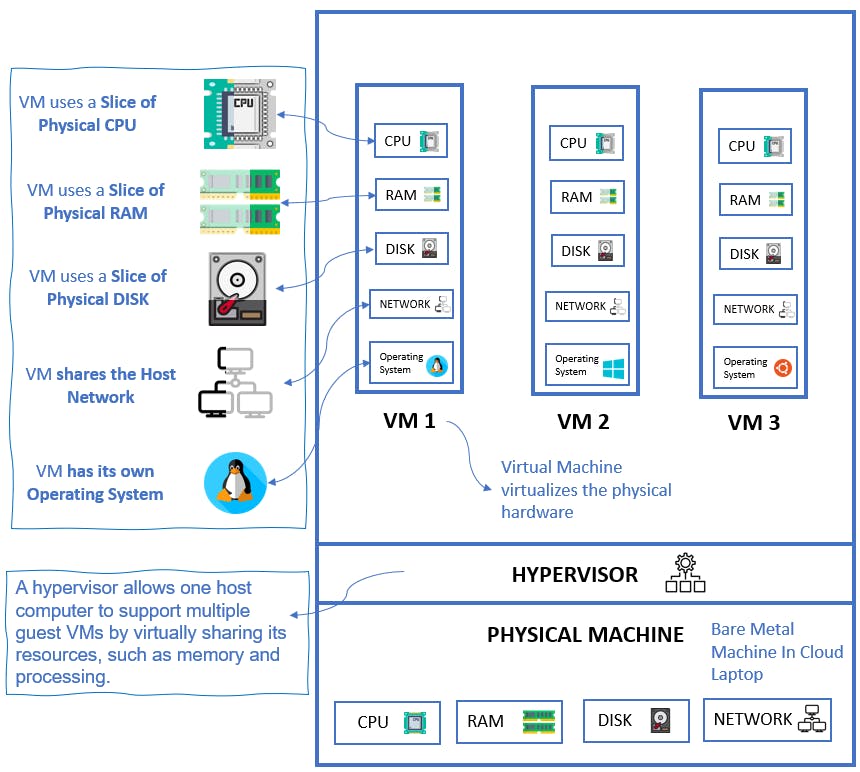
The Good Thing: 👍
- Now we were able to run multiple applications on one server.
- We needed a hypervisor that creates and runs Virtual Machines (VMs).
- Each VM has its own OS where we could run our application.
- VM basically virtualized the physical hardware
The Bad Thing: 👎
Because every VM requires its own OS, each OS consumes:
- CPU
- RAM
- Storage
that could have been used to power other applications
Each OS also requires patching and Licences
- Migrating and moving VM workloads is difficult
- VMs are slow to start and less portable
We needed something else...
Containers to the Rescue! ❤️
As our major problem was that each VM has its own OS, the containers scraped that part altogether. Instead, the container uses the host OS. This allows us to free up the CPU, RAM, and storage as we are not using a full-blown OS for each container.
On top of that containers are:
- fast to start ✅
- ultra-portable ✅
- It is easy to move container workloads from your laptop to the cloud etc. ✅
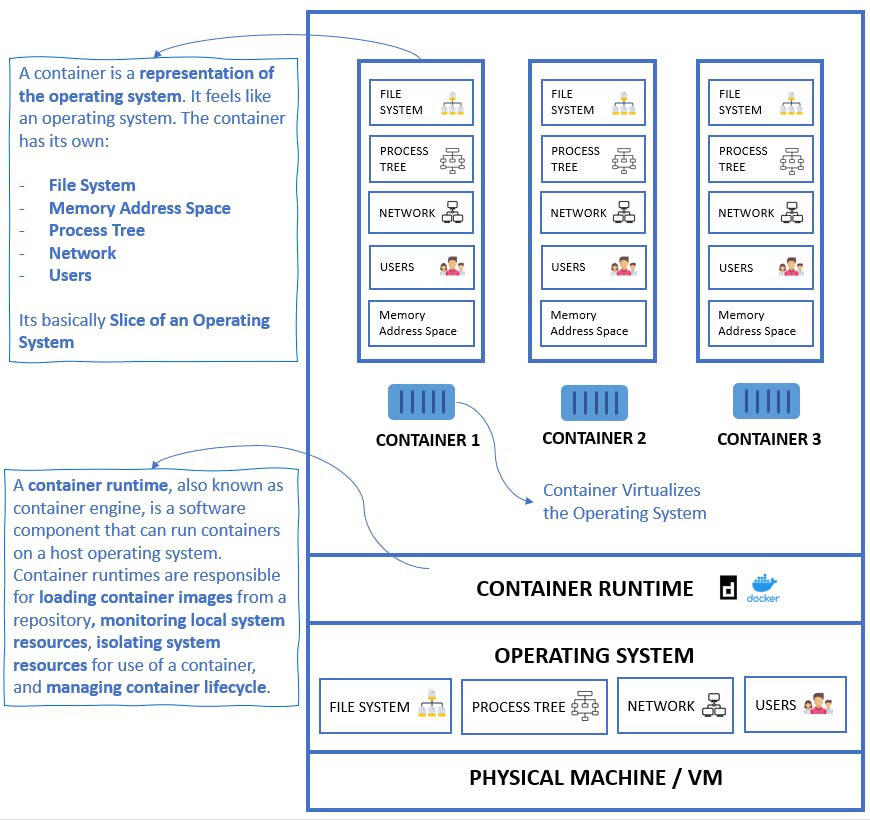
A container is a representation of the operating system. It feels like an operating system. The container has its own:
- File System
- Memory Address Space
- Process Tree
- Network
- Users
It's basically a slice of an Operating System
While a VM needs a hypervisor, the container needs a container runtime to manage the containers.
💭 But how are containers able to virtualize the OS?
Time to Dive Deeper... 🤿🌊
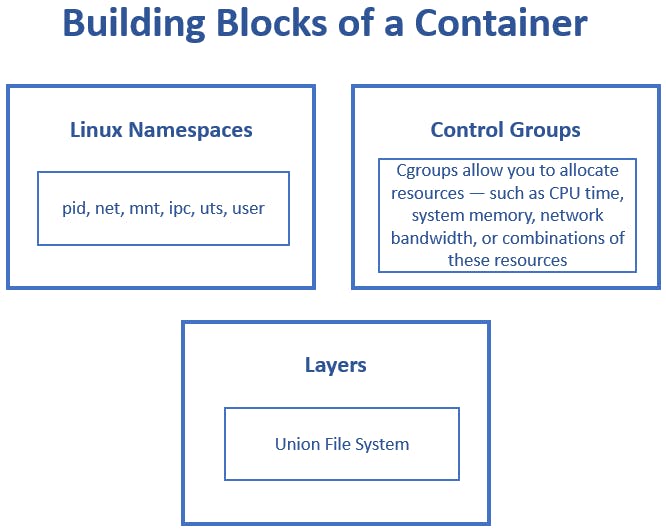
The containers are comprised of 3 things:
- Namespaces
- Controls Groups (Cgroups)
- Layers
What are Namespaces?
According to Wikipedia:
“Namespaces are a feature of the Linux kernel that partitions kernel resources such that one set of processes sees one set of resources while another set of processes sees a different set of resources.”
Basically, the important feature of the namespaces is that they isolate processes from each other. On a machine where different services are running, isolating each service and its related processes means that we can have better security and better chances of not breaking anything if we screw up making some changes.
When developers use containers for development, the container gives the developer an isolated environment that looks and feels like a complete OS/VM when it isn't. It's a process running on the machine. If you start two containers on the same system, these containers would be isolated from each other.
Types of Namespaces
Within the Linux kernel, there are different types of namespaces. Each namespace has its own unique properties:
User namespace (user): A user namespace allows isolating the user running inside the container from the one in the host.
Process ID namespace (PID): A process ID (PID) namespace assigns a set of PIDs to processes that are independent of the set of PIDs in other namespaces. The first process created in a new namespace has PID 1 and child processes are assigned subsequent PIDs. If a child process is created with its own PID namespace, it has PID 1 in that namespace as well as its PID in the parent process’ namespace.
Network namespace (net): A network namespace is a logical copy of the network stack from the host system. Network namespaces are useful for setting up containers or virtual environments. Each namespace has its own IP addresses, network interfaces, routing tables, and so forth.
Mount namespace (mnt): A mount namespace has an independent list of mount points seen by the processes in the namespace. This means that you can mount and unmount filesystems in a mount namespace without affecting the host filesystem.
Interprocess communication namespace (IPC): IPCs handle the communication between processes by using shared memory areas, message queues, and semaphores
UNIX Time-sharing namespace (UTC): UTS namespace allows for the segregation of hostnames. Basically, it allows the same system to appear to have different host and domain names for different processes.
What are Cgroups?
As the name Control Group suggests, the Cgroup controls and isolates the resource usage (CPU, memory, disk I/O, network, etc of a collection of processes. It's a Linux Kernel feature.
With Cgroups you can:
- Limit Resouces: You can limit how much a particular resource (CPU, memory, etc.) can be used by a process by configuring the Cgroup.
Prioritize: You can prioritize which process should get resources when there is resource contention
Account: You can monitor and report resource limits at the Cgroup level.
Control:You can change the status (frozen, stopped, or restarted) of all processes in a Cgroup with a single command.
Cgroups are a very important component of containers there are often multiple processes running in a container that you need to control together.
What are Layers?
On to that later in the journey...
So Basically...
If you really see what a container does is that through isolation provided by the namespaces and the resources provided to it by the Cgroups, It mimics the behavior of an OS without being an OS.
As namespace and Cgroups are Kernel features, the containers use the Host OS kernel instead of having their own as VMs do by having a full-blown OS.
The Beginning of Docker...
Even Before Docker
In 2006, engineers at Google invented the Cgroups. We know that this is a feature of the Linux kernel that isolates and controls resource usage for user processes.
These processes can be put into namespaces, essentially collections of processes that share the same resource limitations.
The First Container...
Because of cgroups and namespace, we were able to make the Linux containers (LXC). LXC took advantage of groups and namespace isolation to create a virtual environment with a separate process and networking space.
Docker
The problem with LXC was that you needed the knowledge of cgroups and namespaces to setup them up.
Docker made things easier. With Docker Daemon building images and managing the containers was made easier.
The Docker daemon was a monolithic binary. It contained all of the code for the Docker client, the Docker API, the container runtime, image builds, etc.
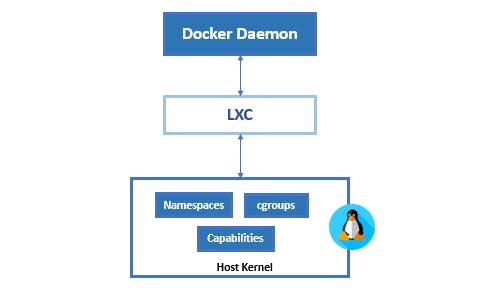
Libcontainer replaces LXC
Docker developed libcontainer as a replacement for LXC as unlike LXC libcontainer was platform-agnostic that provided Docker with access to the fundamental container building blocks that exist inside the OS.
Making Docker Daemon modular
As the Daemon was monolithic it was difficult to add more features to the daemon and it was getting slower.
The aim was to break out as much of the functionality as possible from the daemon and reimplement it in smaller specialized tools.
All of the container execution and container runtime code was entirely removed from the daemon and refactored into small, specialized tools.
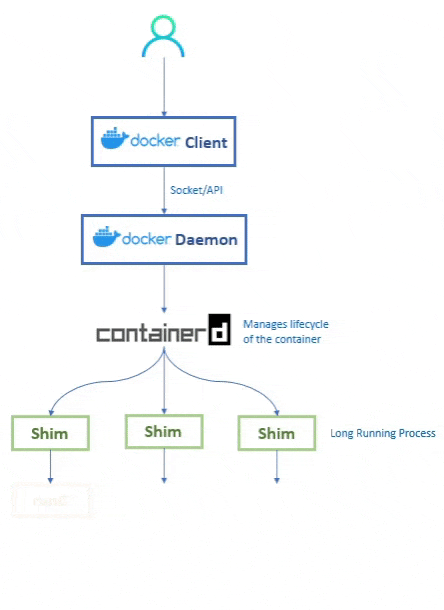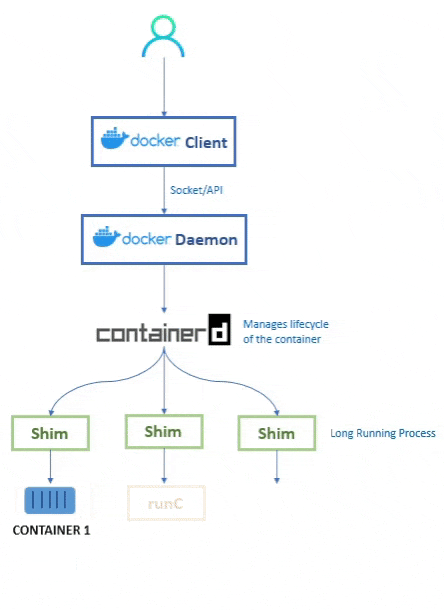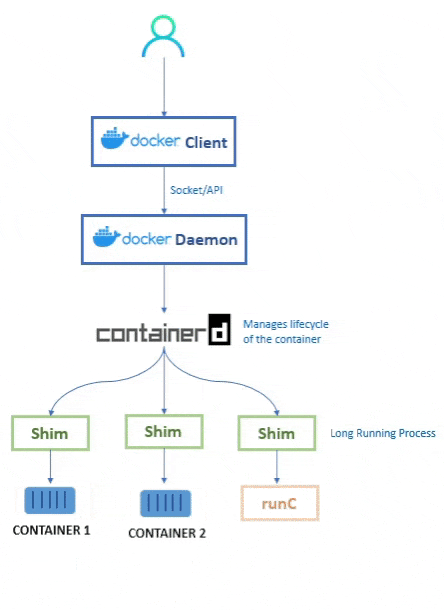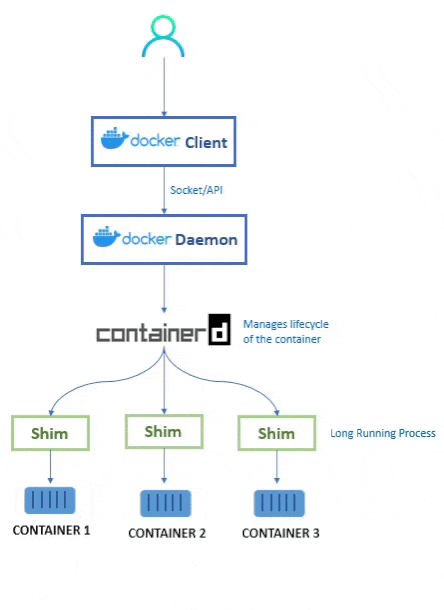
💭 So how does the daemon create the containers now?
When the user types their command into the Docker CLI, the Docker Client then sends the request (REST API) to the Docker Daemon.
As the Docker Daemon is now broken down, it doesnt know how to create the container. Hence it calls conainterd.
Even containerd doesnt know how to create the container. Containerd is responsible for container lifecycle operations such as; starting and stopping containers, pausing and un-pausing them, and destroying them.
Instead, containerd uses runc to create the containers. It converts the required Docker image into an OCI bundle and tells runc to use this to create a new container.
runc then talks to the OS Kernel and does the neccessary stuff to create the container (in Linux these include namespaces and cgroups)
The container process is started as a child-process of runc, and as soon as it is started runc will exit.
💭 What's the purpose of Shim?
As we are removing the dependency from the daemon, the shim helps us achieve that.
So when once a container’s parent runc process exits, the associated containerd-shim process becomes the container’s parent process.
Now the container doesn't need the daemon to keep them alive. This means that we can upgrade the daemon without killing the containers.
Some of the responsibilities of the shim are:
Keeping any STDIN and STDOUT streams open so that when the daemon is restarted, the container doesn’t terminate due to pipes being closed etc.
Reports the container’s exit status back to the daemon.
Open Container Initiative (OCI)
Open Container Initiative The Open Container Initiative is an open governance structure for the express purpose of creating open industry standards around container formats and runtimes.
Established in June 2015 by Docker and other leaders in the container industry, the OCI currently contains three specifications: the Runtime Specification (runtime-spec), the Image Specification (image-spec), and the Distribution Specification (distribution-spec).
Container Runtimes
We know that containerd, rkt, cri-o are container runtimes, but what really goes under the hood when we type for example
docker run ...
This is what happens according to opensource:
If the image is not available locally, the image is pulled from an image registry
The image is extracted onto a copy-on-write filesystem, and all the container layers overlay each other to create a merged filesystem
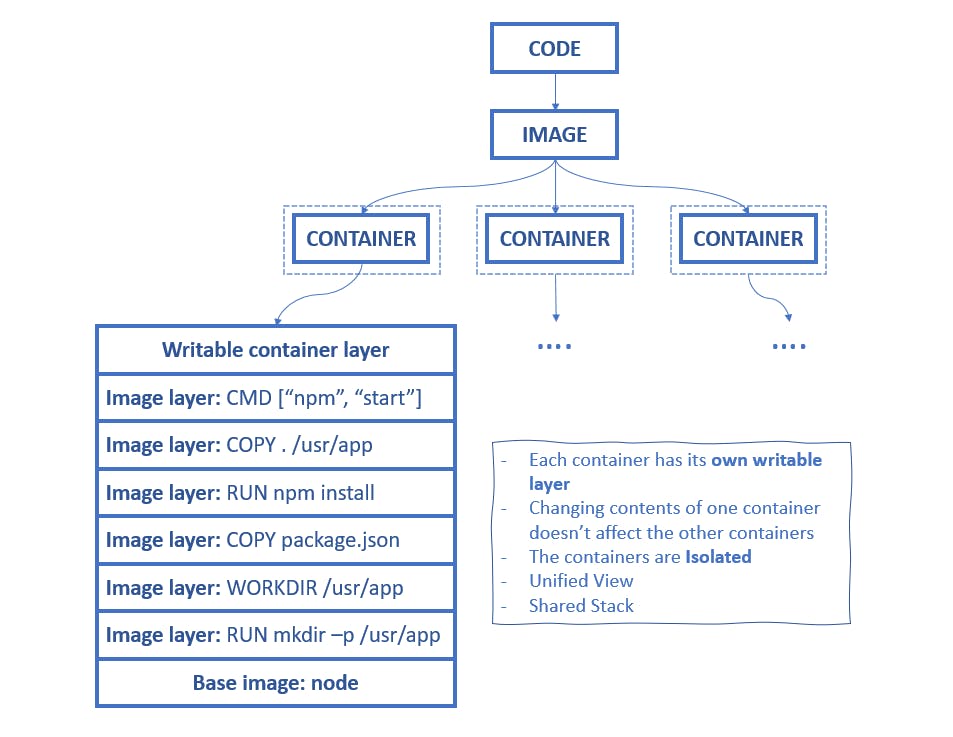
The image shows that each container has a writable layer, so changing the contents of one container does not affect the other container.
A container mount point is prepared
Metadata is set from the container image, including settings like overriding CMD, ENTRYPOINT from user inputs, setting up SECCOMP rules, etc., to ensure the container runs as expected
The kernel is alerted to assign some sort of isolation, such as process, networking, and filesystem, to this container (namespaces)
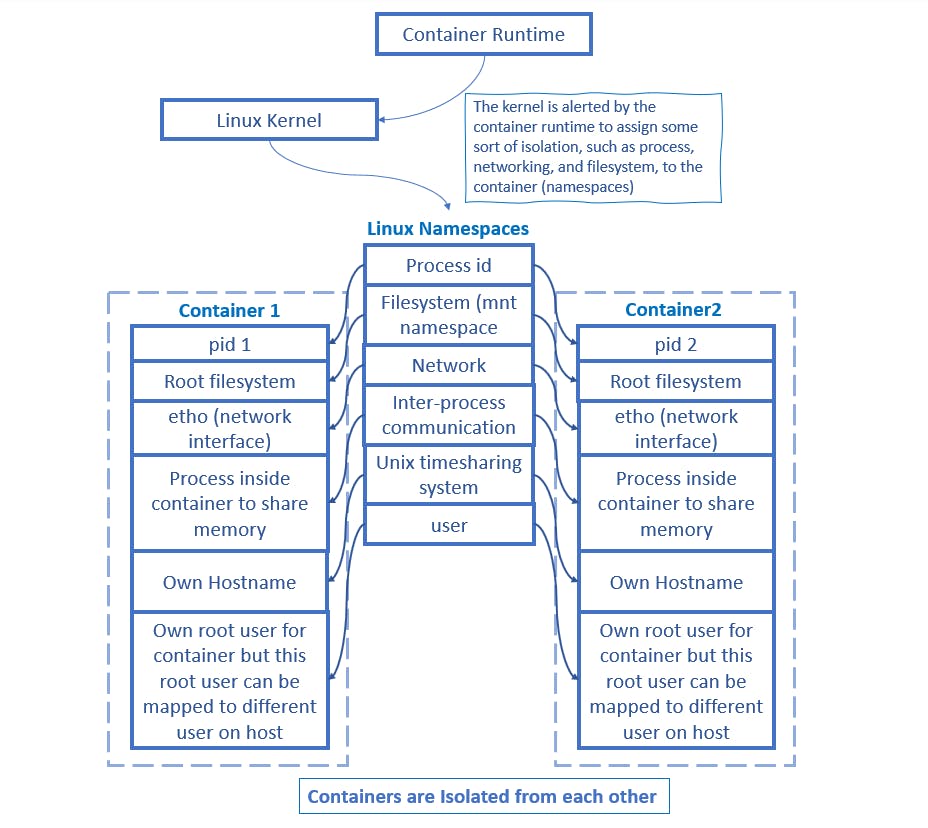
The kernel is also alerted to assign some resource limits like CPU or memory limits to this container (cgroups)
A system call (syscall) is passed to the kernel to start the container
SELinux/AppArmor is set up
Container runtimes take care of all the above
Conclusion
We understood why and how containers became a thing. We also learned about the internals of containers and dockers. Finally, we learned about the OCI and the working of container runtimes :)
Resources
How Containers Work? by Saiyam Pathak
Deep Dive Dockers by Nigel Poulton
What Are Namespaces and cgroups, and How Do They Work? by nginix